

图表内容
Transformer模型通过加入了注意力机制更好地关联了参数
Transformer介绍
ulti-Head Attention
Multi-Head Attention
Concat
Scaled Dot-Product
Attention
ξ源:CSDN

研究报告节选:
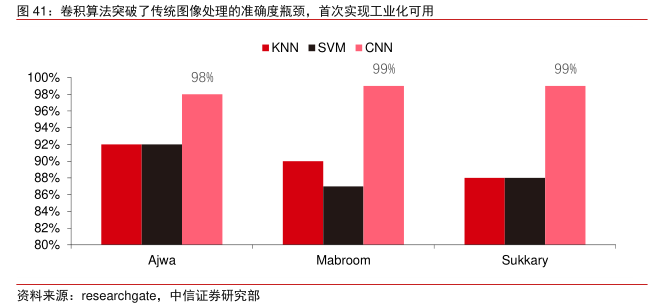
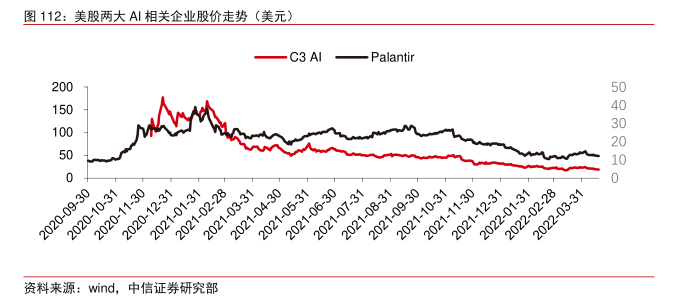
在神经网络算法发展的过程中,Transformer 模型在过去五年里成为了主流,整合了过去各种零散的小模型。Transformer 模型是谷歌在 2017 年推出的 NLP 经典模型(Bert就是用的 Transformer)。模型的核心部分通常由两大部分组成,分别是编码器与解码器。编/解码器主要由两个模块组合成:前馈神经网络(图中蓝色的部分)和注意力机制(图中玫红色的部分),解码器通常多一个(交叉)注意力机制。编码器和解码器通过模仿神经网络对数据进行分类与再次聚焦,在机器翻译任务上模型表现超过了 RNN 和 CNN,只需要编/解码器就能达到很好的效果,可以高效地并行化。