
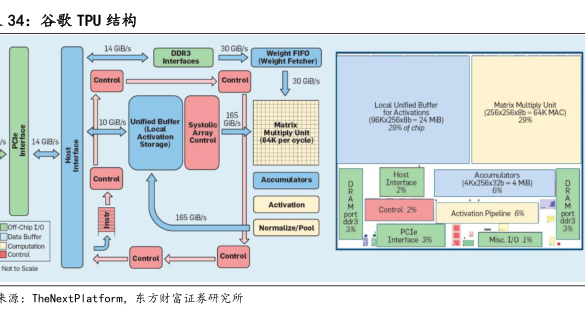



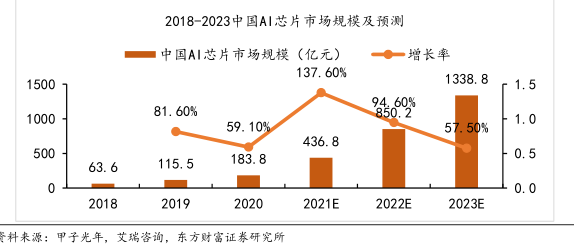

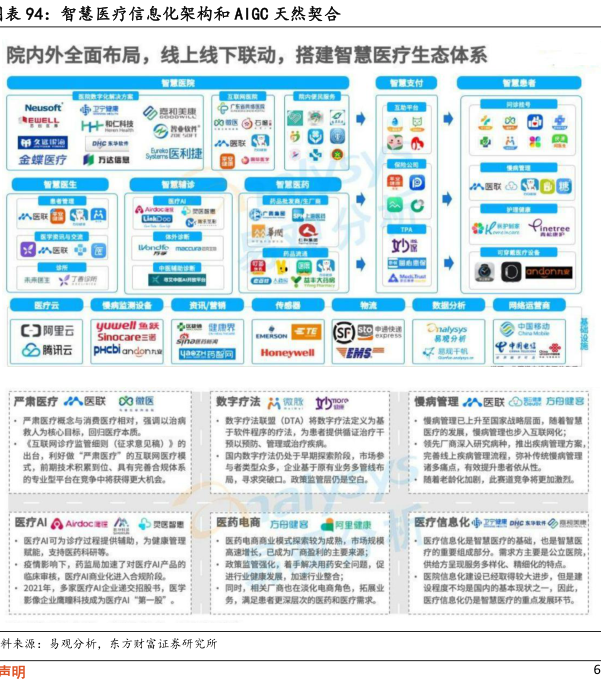

图表内容
Transformer模型结构示意
Output
Probabilities
Scaled Dot-Product Attention
Sottmax
MatMul
Linear
SoftMax
Add Norm
Feed
Forward
Add Norm
Multi-Head
Feed
Attention
Forward
Nx
Nx
Add Norm
Masked
Multi-Head
Multi-Head
Attention
Attention
Scaled Dot-Product
Positional
Positional
Encoding
Encoding
Output
Embedding
Embedding
Inputs
Outputs
(shifted right)
《Attention is all youneed》
东方对富证券研究所

