
图表内容
(类反馈的强化学习训练示意图
收集人工反馈
训练奖励模型
使用PPO优化策路
One post with
mpled from
judged by a
human are ted
summary for the
post.
dre
The reward
a reward for the
summary.
mary of the
Learning to summarize from human feedback
东方财富证券研究所

研究报告节选:
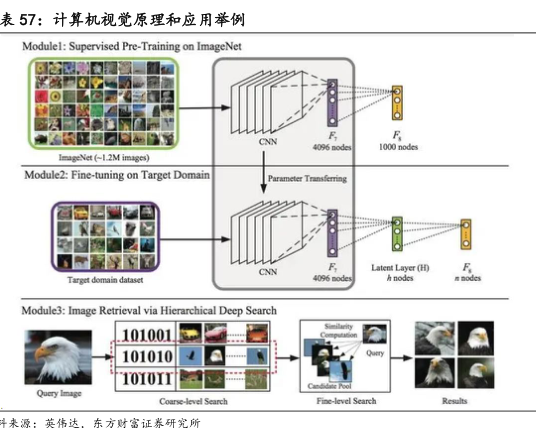
ChatGPT 的人类反馈强化学习训练过程包括三个阶段。第一阶段,收集人工反馈数据,训练监督策略模型。为了让 GPT-3.5 初步具备理解指令的意图,首先会在数据集中随机抽取问题,由人类标注人员给出高质量答案,然后用这些人工标注好的数据来微调 GPT-3.5 模型。第二阶段,训练奖励模型。使用第一阶段生成的模型,对于每个问题生成多个不同的回答,由人类标注者对这些结果综合考虑给出排名顺序。第三阶段,采用近端策略优化(Proximal Policy Optimization,PPO)强化学习来优化策略。对于每个问题,使用 PPO 模型生成回答,并用上一阶段训练好的奖励模型给出质量分数;通过回报分数的依次传递产生策略梯度,不断优化 PPO 模型参数。对第二和第三阶段进行迭代,能够训练出更高质量的 ChatGPT 模型。