


图表内容
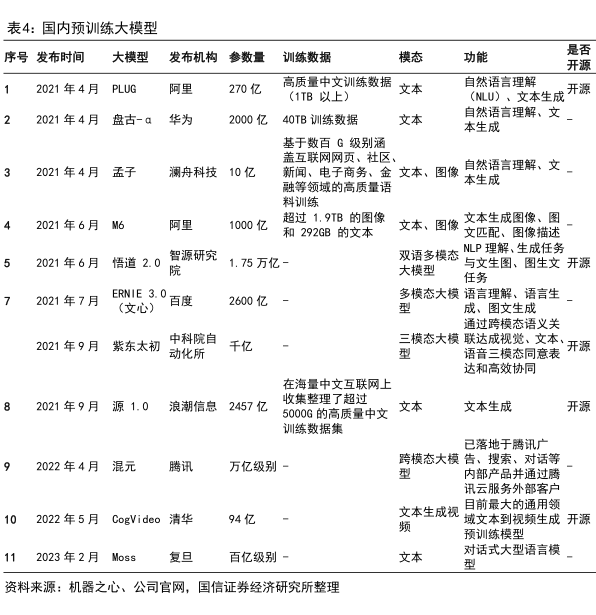
表4:国内预训练大模型
序号发布时间
大模型
发布机构
参数量
训练数据
模态
功能
是否
开源
2021年4月PLUG
阿里
270亿
高质量中文训练数据
文本
自然语言理解
(1TB以上)
(NU)、文本生成
开源
2021年4月盘古-a
华为
2000亿40TB训练数据
文本
自然语言理解、文
本生成
基于数百G级别涵
盖互联网网页、社区、
2021年4月孟子
澜舟科技10亿
新闻、电子商务、金文本、图像
自然语言理解、文
融等领域的高质量语
本生成
料训练
超过1.9TB的图像
文本生成图像、图
2021年6月M6
阿里
1000亿
文本、图像
和292GB的文本
文匹配、图像描述
智源研究
双语多模态
LP理解、生成任务
2021年6月悟道2.0
1.75万亿-
大模型
与文生图、图生文开源
任务
2021年7月
ERNIE 3.0.
多模态大模语言理解、语言生
(文心)
百度
2600亿-
成、图文生成
通过跨模态语义关
2021年9月紫东太初
中科院自
千亿
三模态大模联达成视觉,文本开源
动化所
语音三模态同意表
达和高效协同
在海量中文互联网上
2021年9月源1.0浪潮信总2457亿
收集整理了超过
5000G的高质量中文
文本
文本生成
开源
训练数据集
已落地于腾讯广
2022年4月混元
腾讯
万亿级别
跨模态大模告、搜索、对话等
内部产品并通过腾
讯云服务外部客户
目前最大的通用领
2022年5月CogVideo清华
94亿
文本生成视
域文本到视频生成开源
预训练模型
2023年2月Moss
复旦
百亿级别一
文本
对话式大型语言模
资料来源:机器之心、公司官网,国信证券经济研究所整理

