图表内容
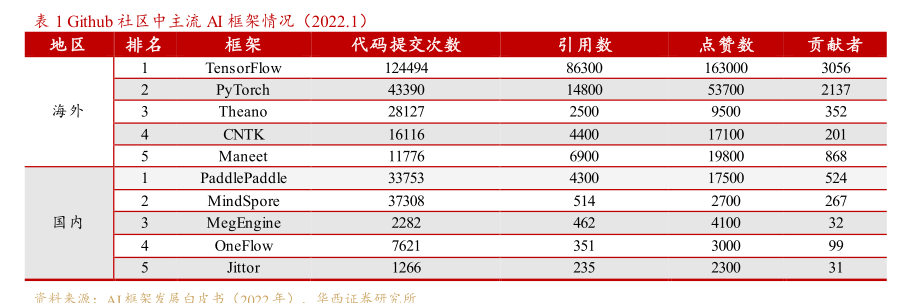
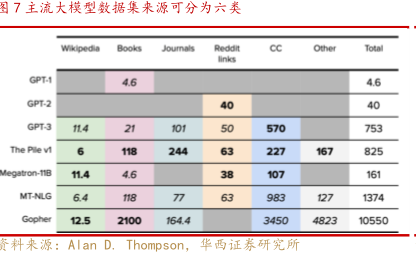
图7主流大模型数据集来源可分为六类
Books
cc
Other
Total
GPT-1
4.6
GPT-2
GPT-3
egatron-118
11.4
4.6
MT-NLG
Gopher
12.5
164.4
资料来源:Alan D
Thompson
华西证券研究所
研究报告节选:
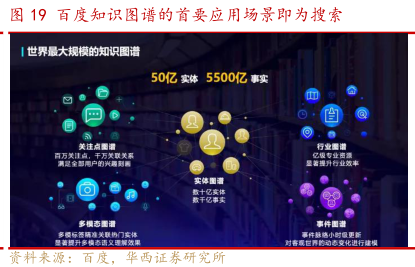
国内厂商在中文训练数据方面有一定优势,以百度为例,ERNIE 3.0 的中文预训练语料数量最多,主要来源为 ERNIE 2.0(包括百科、Feed 等)、百度搜索(包括百家号、知乎、铁算盘、经验)、网络文本、QA-long、 QA-short、Poetry 2&Couplet 3、医学、法律、金融等领域的特定数据以及百度知识图谱(超过 5000 万条事实)。