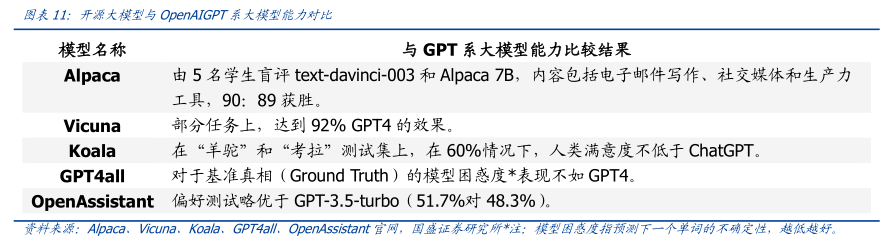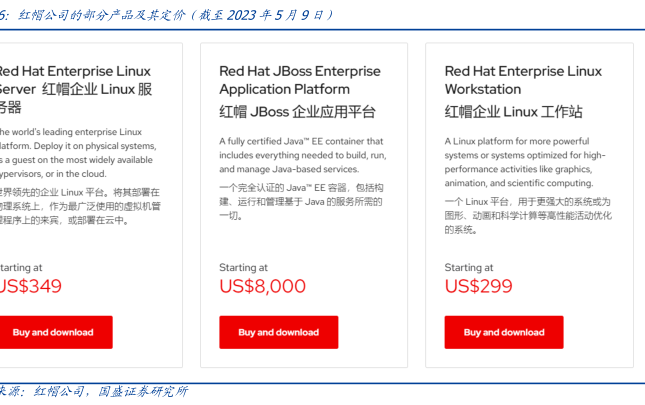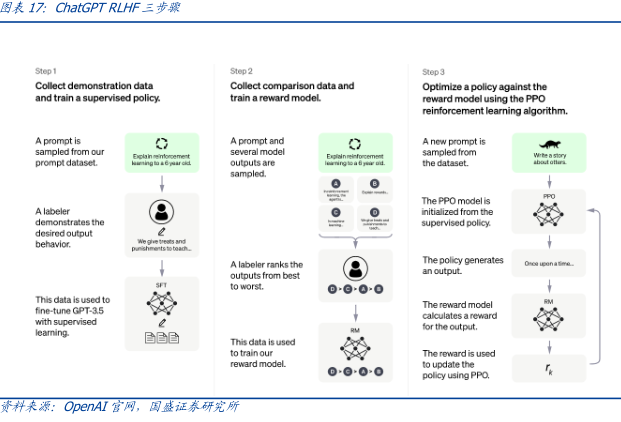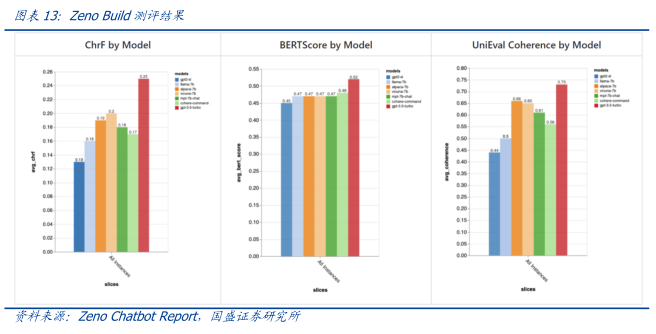
图表内容
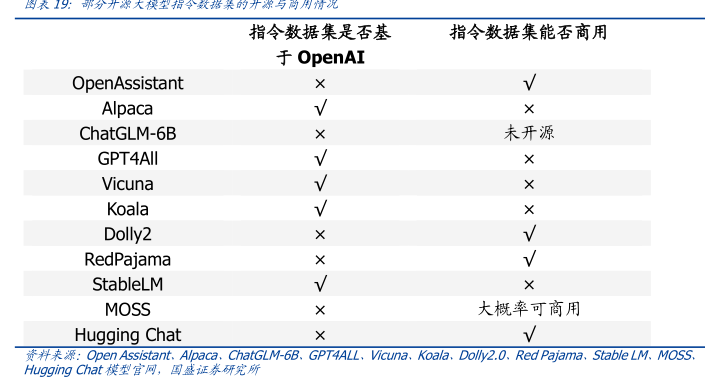
表8:大模型训练和推理的一殷流程
步骤一:预训练
预训练数据集
1预训练→
基础模型
·无监督学习
步操二:微调
2微调
徽调模型
通过在人工标注的数据集上训继优化摸型
”“安全
用户输入
步骤三:推理
3推罗
与人在线,实时文互
使用已经利蛛好的模型生成响应
结果输出
科来源:《Generative Pre-Trained Transformer for Design Concept Generation.An Exploration.》,国盛证泰
研究报告节选:
3.1 超大模型和大模型分别多大? 预训练赋予模型基本能力。在自然语言处理(NLP)中,预训练是指在特定任务微调之前,将语言模型在大量文本语料库上训练,为模型赋予基本的语言理解能力。在预训练过程中,模型被训练以根据前面的上下文预测句子中的下一个单词。这可以通过掩盖一些输入中的单词并要求模型预测它们的方式进行,也可以采用自回归的方法(例如 GPT),即根据句子中的前面单词预测下一个单词。 预训练模型通常包括大量的参数和对应的预训练数据(通常用标识符即 Token 的数量衡量)。2017 年谷歌大脑团队 Transformer(变换器)模型的出现,彻底改变了 NLP 的面貌,使得模型可以更好地理解和处理语言,提高 NLP 任务的效果和准确性。