
图表内容
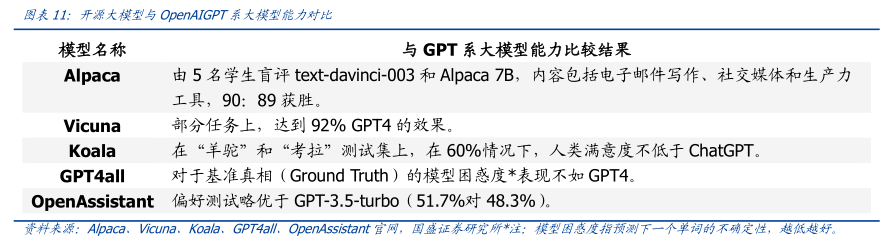
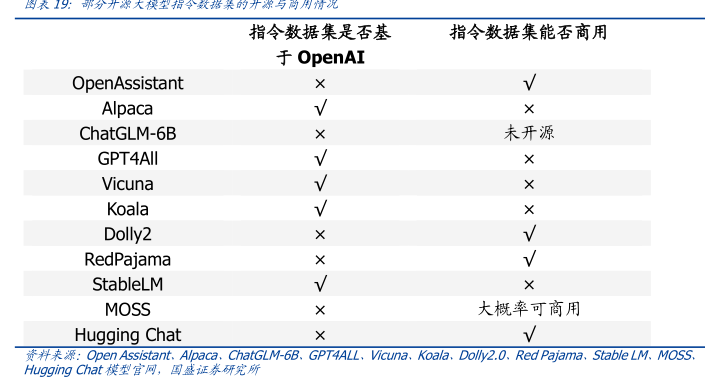
图表11:开源大模型与Open4IGPT系大模型能力对比
模型名称
与GPT系大模型能力比较结果
Alpaca
由5名学生盲评text-davinci-003和Alpaca7B
内容包括电子邮件写作、社交媒体和生产力
工具,90:89获胜。
Vicuna
部分任务上,达到92%GPT4的效果
Koala
在“羊驼”和“考拉”测试集上,在60%情况下,人类满意度不低于ChatGPT。
GPT4all
对于基准真相(Ground Truth)的模型困惑度*表现不如GPT4。
OpenAssistant
偏好测试略优于GPT-3.5-turb0(51.7%对48.3%)。

