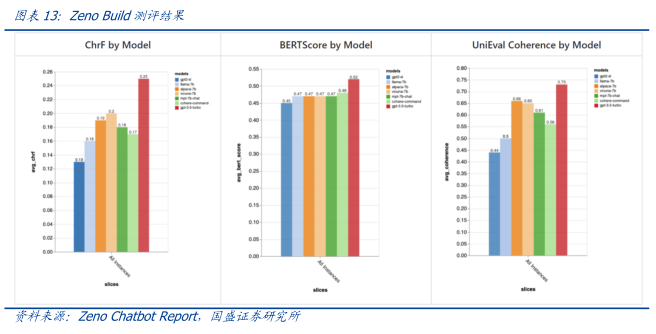
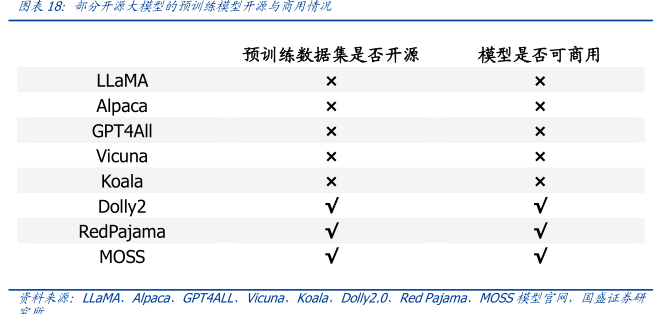
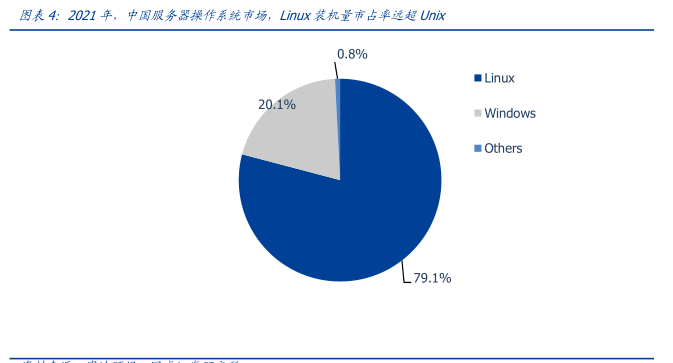

图表内容
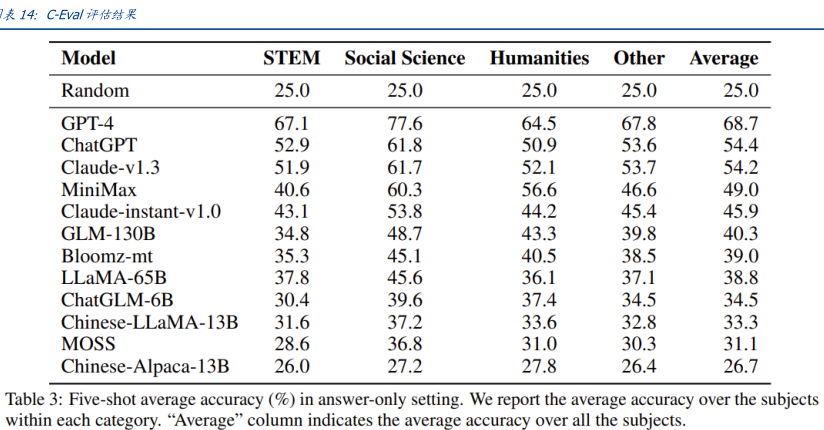
表14:C-Eval评估结果
Model
STEM
Social Science
Humanities
Other
Average
Random
25.0
25.0
25.0
25.0
25.0
GPT-4
67.1
77.6
64.5
67.8
68.7
ChatGPT
52.9
61.8
50.9
53.6
54.4
Claude-v1.3
51.9
61.7
52.1
53.7
54.2
MiniMax
40.6
60.3
56.6
46.6
49.0
Claude-instant-v1.0
43.1
53.8
44.2
45.4
45.9
GLM-130B
34.8
48.7
43.3
39.8
40.3
Bloomz-mt
35.3
45.1
40.5
38.5
39.0
LLaMA-65B
37.8
45.6
36.1
37.1
38.8
ChatGLM-6B
30.4
39.6
37.4
34.5
34.5
Chinese-LLaMA-13B
31.6
37.2
33.6
32.8
33.3
MOSS
28.6
36.8
31.0
30.3
31.1
Chinese-Alpaca-13B
26.0
27.2
27.8
26.4
26.7
Table 3:Five-shot average accuracy (%)in answer-only setting.We report the average accuracy over the subjects
within each category."Average"column indicates the average accuracy over all the subjects.

