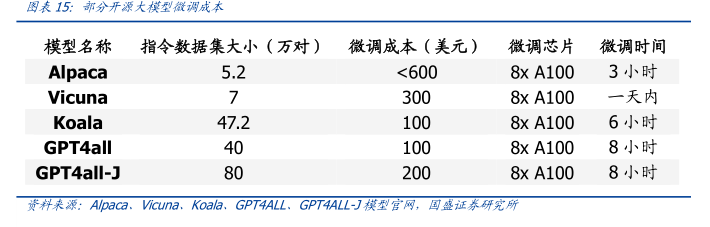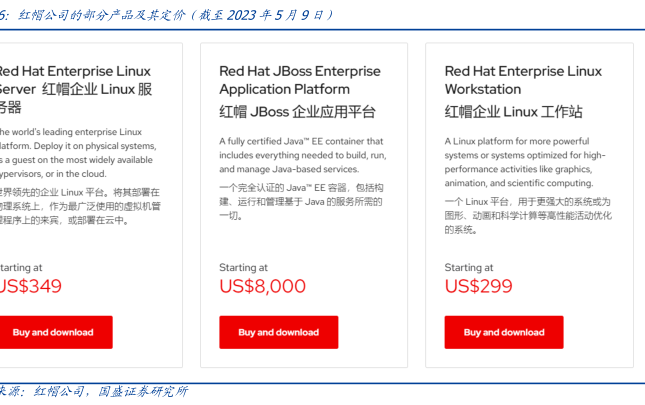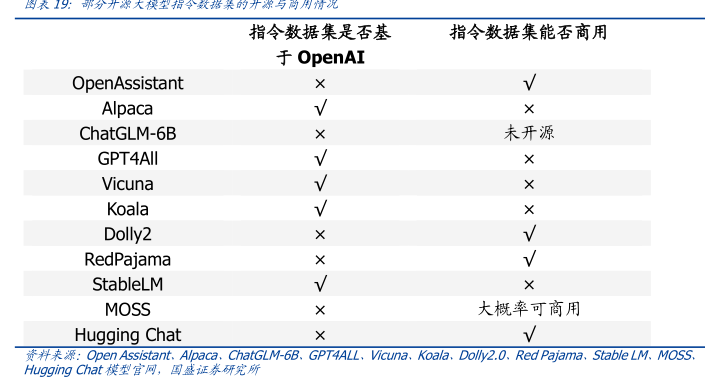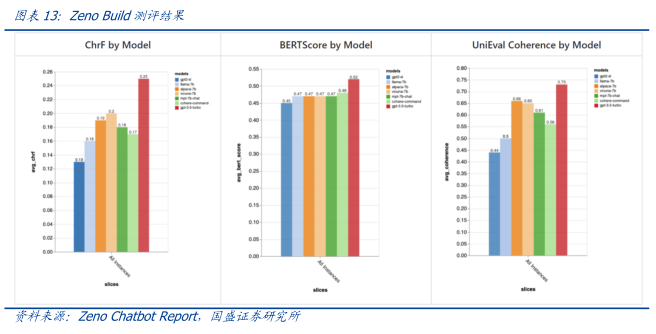
图表内容
Cross-Modal Retrieval
Audio
Depth
Text
rackle of a Fire
Baby Cooing
Embedding-Space Arithmetic
3)Audio to Image Generation
Waves
夹源:ImageBind:One Embedding Space To Bind Them All)
国盛证券研究所

研究报告节选:
ImageBind 开源大模型可超越单一感官体验,让机器拥有“联想”能力。5 月 9 日,Meta 公司宣布开源多模态大模型 ImageBind。该模型以图像为核心,可打通 6 种模态,包括图像(图片/视频)、温度(红外图像)、文本、音频、深度信息(3D)、动作捕捉传感(IMU)。相关源代码已托管至 GitHub。该团队表示未来还将加入触觉、嗅觉、大脑磁共振信号等模态。 从技术上讲,ImageBind 利用网络数据(如图像、文本),并将其与自然存在的配对数据(如音频、深度信息等)相结合,以学习单个联合嵌入空间,使得 ImageBind 隐式地将文本嵌入与其他模态对齐,从而在没有显式语义或文本配对的情况下,能在这些模态上实现零样本识别功能。 目前 ImageBind 的典型用例包括:向模型输入狗叫声,模型输出狗的图片,反之亦可;向模型输入鸟的图片和海浪声,模型输出鸟在海边的图片,反之亦可。